Ruby 3.2 highlights
As tradition dictates, we got our annual release of Ruby on Christmas Day. While I may have been a little ambitious1 about adding support for it to the Prometheus Ruby client on the day of release, it’s got some features I’m excited about, and I thought I’d use the Christmas downtime to write a short round-up.
Production-ready YJIT
In the circles I run in, this is by far the feature that’s received the most fanfare.
YJIT is an optimising just-in-time (JIT) compiler built by Shopify to improve the performance of their applications. The initial version landed in Ruby 3.1, but was kept behind the --yjit flag as it was experimental.
With the release of Ruby 3.2, it’s considered production-ready and is enabled by default. In fact, Shopify have been running it in production and are seeing a roughly 10% speedup across their different workloads.
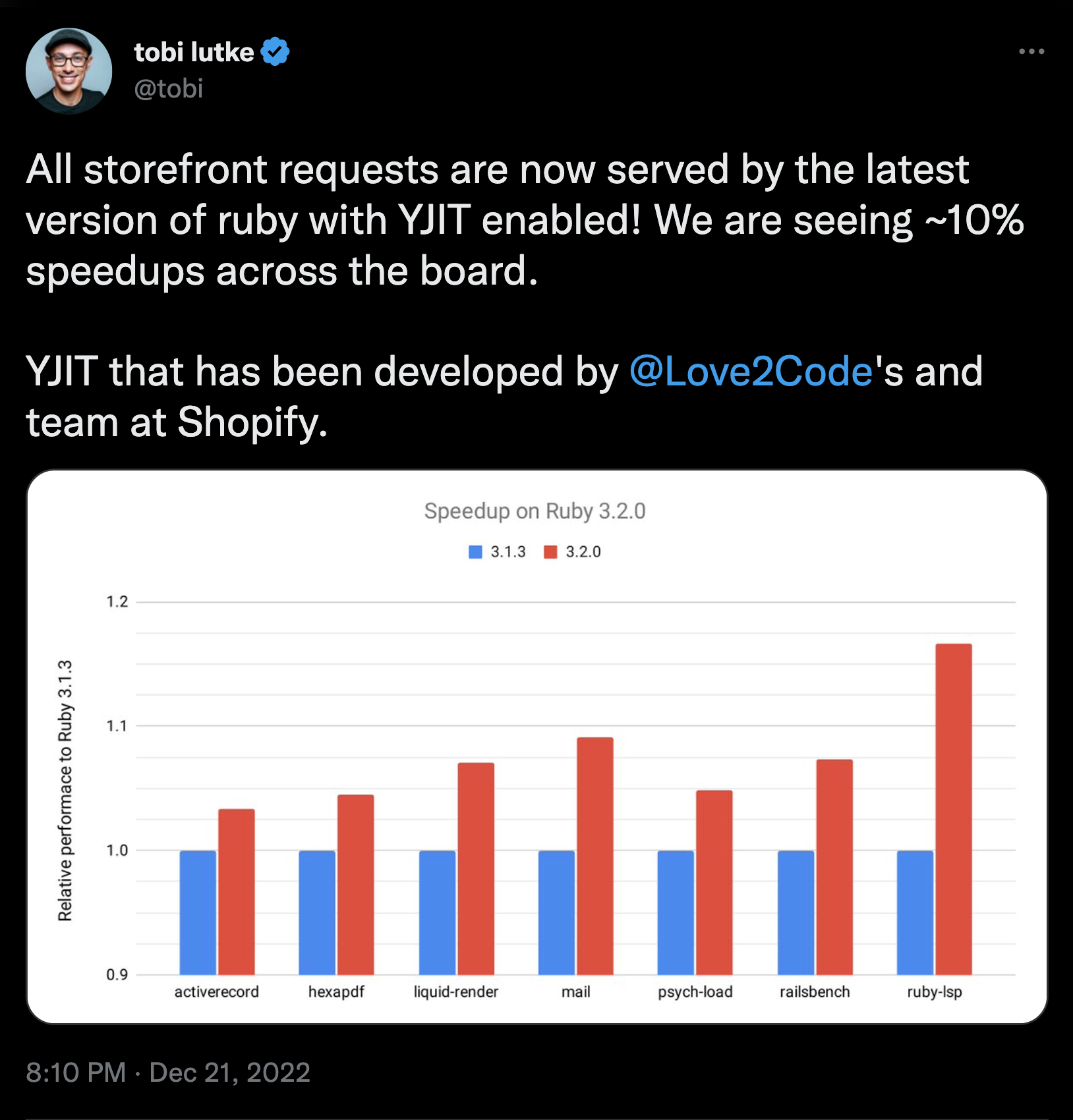
If you want to follow along with the performance gains being made by the YJIT team, they have a site where they regularly publish benchmark results.
Regular expression timeouts
It’s peak SRE nerd to be excited about this, but screw it, I’m an SRE nerd and I’m excited.
Many languages — Ruby included — come with a form of regular expressions known as Perl Compatible Regular Expressions (PCRE). They’re popular because of the extra matching features they have2, but come with one big downside: runtime complexity.
It’s easy to construct a PCRE that has pathologically slow matching behaviour on certain inputs. StackOverflow famously had a half hour outage because of a regular expression which consumed huge amounts of CPU time when run on a particular post.
Ruby 3.2 introduces a timeout setting on its regular expression class. A timeout can be specified globally and later overridden on a per-expression basis.
# Setting the regex timeout globally (in seconds)
Regexp.timeout = 1.0
# Setting the regex timeout for a specific expression
Regexp.new('^\d+$', timeout: 2.0)
If evaluating the expression against an input takes longer than the timeout, a Regexp::TimeoutError will be raised.
It’s likely that you’ll want to optimise any regular expression in your codebase that regularly times out, as it indicates a performance problem and will lead to some failed requests. The great thing about having a timeout is that you fail a few requests rather than having a full-on outage.
Immutable value objects
My last highlight of Ruby 3.2 is something I’ve wanted for almost as long as I’ve written the language3: a simple, immutable value object in the standard library.
Struct is the closest thing we’ve had, but it’s mutable, has a number of extra behaviours that can bite you4, and requires you to explicitly opt in to using keyword args by specifying keyword_init: true when defining it.
The new class — Data — lets you define immutable value objects and gives you a convenient way to produce copies with one or more fields changed.
Clothing = Data.define(:garment, :colour, :size)
blue_jorts = Clothing.new(
garment: "jorts",
colour: "blue",
size: "L",
)
green_jorts = blue_jorts.with(colour: "green")
Having previously used libraries like Tom Crayford’s Values to get around the lack of a good value type in the standard library, it’s great to finally have this included.
There’s plenty more to check out in Ruby 3.2. These are just my highlights, which I hope you found useful.
Merry Christmas everyone! ✌🏻💖🎄
-
While Ruby 3.2 itself is ready to use, and works just fine on my laptop, there’s a little delay between the official release and providers like CircleCI building container images for it. ↩
-
In Computer Science, there’s a much more strict definition of what constitutes a regular language, and by implication what can be expressed by a regular expression. PCRE’s matching primitives go way beyond what’s allowed in a regular language.
Recently, there has been a shift away from PCRE as the default type of regular expressions, due to their downsides. RE2 is a popular alternative, which foregoes a number of features to achieve linear-time performance. The main Rust implementation of regular expressions is heavily inspired by RE2. ↩
-
If I’m remembering right, I first started learning it in 2012 as a team in my departent was using it and it looked interesting. By 2013 I’d joined their team. ↩
-
As mentioned in the proposal, one non-intuitive behaviour is that
Structhas ato_amethod on it, which returns the values of all its fields as an array. When passed to theArrayfunction, the struct will be treated as a collection and flattened out into the resulting array. ↩